
当社で販売している Linux サーバー HPC-ProServer や HPC-ProFS等のエンタープライズ製品を ハンズフリー に運用するその手法とサービスについて、ご紹介します。運用の手間を省きたいというお客様の要望に向き合い、当社が培ってきた知見及びノウハウと弊社製品のOEM供給元であるDELL社の技術・サービスを組み合わせて、お客様の手間を最大限に低減させる運用サービスを実現します。
Windowsと異なりLinuxでは、一般的には日頃から接する機会が少ないですし、個人で扱うPCと異なり、多人数で共同利用するサーバーであるならば、コンピューターの専門家でもなければ、その運用を自信をもって行うのは難しいと思います。特に、民間企業などで、シミュレーションやデータ解析に必要という理由でサーバーの導入を計画しても、サーバーの運用面を検討した上で、その費用対効果を予測するのはとても難しく、サーバーの導入がハードルの高いものであることも理解できます。
弊社では、そのような導入にまつわるハードルをできるだけ下げて、運用コストを低減できる取り組みを多く取り揃えています。本稿では、導入検討の時点から一つ一つ積み重ねて、どのようなサービスがご提供可能であるかを明らかにします。
尚、ここに挙げたサービスは弊社製品に標準的なサービスの範囲を超えるものが含まれておりますので、詳しくは、弊社営業までお問い合わせください。
導入前の事前検討
サーバーを設置するためには、物理的な設置方法や空調、電源環境を検討する必要があります。HPCテクノロジーズでは、EIA規格の19インチラックに搭載するラックマウントサーバーや、タワー型のサーバー、静かな居室のデスクサイドに設置可能なワークステーション等、多種多様な製品を揃えていますので、お客様の設置環境に応じた製品をご提案することが可能です。
DELL社のサーバー、ストレージ製品は、その構成に応じた重量や消費電力を手軽に計算できるツールが用意されていて、それを元に適切な電力容量、空調能力、耐荷重などを見積もることが可能です。
消費電力試算ツール(EIPT) : https://japancatalog.dell.com/c/isg_eipt/
ラックの設置から検討が必要な場合については、その設置スペースの確保や耐震固定の方法などの検討も必要です。弊社のホームページで以下に計算機導入に向けた事前検討ガイドを掲載していますので、ご参考にしてください。もちろん、新規の設置につきましては設置場所の下見を実施し、万全な体制で納品致します。
ハンズフリーな運用に欠かせない事前準備された Linux OS パッケージ
サーバーを運用する場合、目的となるアプリケーションを動かすためにコンパイラやライブラリ、ヘッダファイルなどの依存関係のあるソフトウェアをインストールしなければならないだけではなく、サーバーとして運用するために、ユーザー認証やデータ共有サービス、時刻同期、セキュリティーソフトなどのソフトウェアもインストールされている必要があります。また、サーバーメーカーから提供されているサーバー管理ソフトウェアなどもインストールが必要ですので、サーバーの導入にあたっては、通常のPCとは異なり、OSに対して様々な準備が必要になることは間違いありません。
HPCテクノロジーズでは、そのようなソフトウェアの要件について、ヒアリングの上で導入時に事前にインストール致します。原則として出荷前の弊社工場にてインストール及び動作確認します。したがって、ハードウェアを導入したものの、目的とするアプリケーションがなかなか稼働しないということはありません。
OSは、RedHat Enterprise Linux はもちろん、その互換OSであるRockyLinuxやAlmaLinuxに対応し、Ubuntuのインストールも可能です。既存環境との兼ね合いや、利用されるアプリケーションの動作条件を踏まえて、ユーザー様と共に検討した上で決定致します。また、長期間サーバーを利用していると、OSのアップデートが必要になる場合もあります。そのような場合に備えて、弊社の技術員が現地でOSのアップデートを行うサービスもございます。
また、サーバー機器にはOSのアップデートだけではなくて、BIOSやさまざまなハードウェアコンポーネントにおけるファームウェアのアップデートも欠かすことができません。DELL社製サーバーのBIOSやファームウェアの多くは、OSからコマンドを実行することでアップデートすることができます。とても手軽にアップデートすることが可能ですので、最新のファームウェアを適用することに対する手間はとても少なくてすみます。
開発環境やアプリケーション、実行環境、環境変数の設定等を事前設定
システムで稼働を目的とするアプリケーションには、ソースからビルドが必要なものもあれば、バイナリで提供されているものもあります。アプリケーションがソースからのビルドを必要とするならば、コンパイラやライブラリが必要になりますし、アプリケーションがバイナリで提供されていたとしても、依存関係のあるOSパッケージのインストールが必要になる場合があります。
そのようなアプリケーションを動作させるための準備や、アプリケーションのインストール、ジョブの実行方法の手順の確立、ユーザーの環境変数への反映などは、計算機システムの運用には欠かすことのできません。そのような手間もノウハウも必要とされる作業については、是非弊社へご依頼ください。
弊社では、ソフトウェアの技術やノウハウだけでなく、ハードウェアに対する深い理解やノウハウも持ち合わせていますので、単にアプリケーションが動くということに留まらず、ハードウェアが備えるパフォーマンスを最大限引き出すシステムチューニングを実施し、アプリケーションを高い効率で稼働させることが可能となります。
スムーズな物理設置作業
機器の搬入にあたっては、エレベーターの有無や段差などで大きく作業の負担が変わってまいりますため、当社では、そのような搬入経路については事前に確認させて頂くようにしております。
サーバーやストレージ機器の設置で重要な点は、それらの機器がとても重いことです。1Uや2Uサーバーで特にストレージを多く積んでいない場合でも、15~20kg程度の重量がありますし、ストレージや無停電電源装置(UPS)にいたっては、50Kgを超える重量があります。42Uラックに搭載する場合には、一人では搭載できず、2~3名程度の作業員が必要な機器も多いです。
また、サーバーやストレージ機器を取り付けるためのレールは、世代によって形状が異なる場合も多いですし、それに伴い取り付け方も機器によって異なりますので、そのような点における知見もとても重要なものです。また、設置場所によってはとても狭い場所で作業を行う場合も多く、総じて容易な作業ではありません。
サーバー等の機器を輸送するために使用した梱包材も大量なものとなります。その廃棄については、事前にお客様と相談させて頂きますが、弊社にて廃棄まで含めて対応させて頂くと、お客様の負担を大きく低減させることにつながります。尚、梱包材が少量の場合については、お客様のご負担で廃棄頂くお願いをしておりますので、何卒ご了解頂きたいと思います。
ジョブ管理システムによる公平なポリシーに基づくジョブ運用
共同利用環境において予め定められたポリシーに基づいて公平なジョブ割り振りを行うことは、ユーザーのプロジェクトを効率的に進めるためにとても重要なことです。弊社で強くお勧めしているジョブ管理システム Altair Grid Engine (AGE)を導入することで、複数のCPUコアを使用した並列計算や、複数のジョブを連携して実行する依存関係をもたせたジョブ、多量のスクリプトを効率的に実行する配列ジョブ、複雑なジョブ投入オプションを事前設定することでジョブスクリプトのテンプレート化に利用できるJob Classの設定など、様々な機能が利用できます。
ジョブ管理システムがない計算機システムの場合は、サーバー1台または複数台のサーバーごとに1ユーザーまたは1グループを割り当てて、そこで自由に使わせるという運用形態になる場合が多いように見受けられます。1つの研究室内で運用されている計算機システムでは、教授や准教授の先生の指導により、計算機の割当が最適化されて、うまく運用されているケースも多いのですが、複数の研究室で共用される計算機システムでは、調整は難しく、やはりジョブ管理システムによって、公平なポリシーに基づくジョブの割当を行うことが、円満な計算機運用のに効果的です。
近年では、GPUの有効活用がシステム運用で重視される傾向にあります。GPUの利用にあたっては、DockerやSingularityなどのコンテナプラットフォームが一般的に利用されていて、ジョブ管理システムでは、それらのコンテナをジョブ管理システムを介して実行することができます。つまり、そのようなジョブ運用を円滑に行うためにもジョブ管理システムが有効に機能します。
障害アラートメールと簡単なログ採取で、障害対応の負担軽減
サーバーは、サーバー室という無人の空間で稼働するものですので、障害が発生した場合に、LEDなどの視覚に訴える方法では、障害が検知できません。したがって、電子メールやSNMPなどによるネットワークを経由した監視方法が必要になります。HPCテクノロジーズでは、主に電子メールを利用したアラートの仕組みを導入しています。
ただし、ネットワークを経由するシステム監視の可否については、組織のネットワーク・セキュリティーのポリシーに大きく依存しますので、導入時に慎重に検討が必要です。特に電子メールについては、送信時にSMTP-AUTHにより、クライアントから送信側メールサーバへ通信をする際にクライアントに対して認証情報を元に認証を取る方法が主流ですので、特に企業のネットワークに対しては、かなり導入のハードルが高いと言わざるを得ません。障害の検知について電子メールやSNMPによる監視ができなければ、定期的に目視による監視を行うことになります。
DELL社のサーバーについては、TSR(Technical Support Report)と呼ばれる解析に必要なログを集約したzipファイルを取得する仕組みがあります。これはOSに予め必要なパッケージをインストールしてあれば、OS上から実行することが可能であり、HPCテクノロジーズの販売するサーバーでは、その仕組が利用可能です。OS上から取得する方法は、以下に説明しています。
これらの仕組みにより、障害時の対応について、サーバー管理者の方の負担は大きく減らすことが可能となります。
修理はオンサイト対応
ログを取得して解析を行ったあとは、現地で修理を行います。デル機器の修理にあたっては、以下のような段取りで一連の修理作業が進みます。
障害通知
アラートメールまたはお客様からの障害の連絡
ログ解析、原因の切り分け
HPCテクノロジーズ及びデル社にて、症状及びログを解析して、障害原因を特定します。
サポート手配完了
障害部位を特定し、パーツの在庫を確認した上で、サポートが受付されます。
デル社のサポート請負会社からのアポイント連絡
パーツの配送やエンジニア訪問時間の決定、訪問先の確認、作業にあたっての注意事項、入構にあたっての事前申請の有無の確認等を実施し、確実に修理が進むように調整します。
パーツ配送
アポイント連絡時に調整した時間帯にパーツが配送されます。
エンジニア訪問
アポイント連絡時に調整した時間にエンジニアが訪問します。
修理、作業報告
訪問したエンジニアを障害の発生している機器へエスコートして頂きます。また、エンジニアがサーバーのステータスを確認するために、iDRACの画面またはOMSA(OpenManage Server Administrator)の画面を表示して頂く必要があります。作業中は、常に立ち会う必要はありませんが、作業員との連絡手段は確保しておいてください。作業が終了しましたら、エンジニアは作業報告(書面または電子メール)をして、現場を退出致します。
パーツ返却
修理交換したパーツは、作業日の翌々営業日に回収業者が引き取りにきます。日中帯で時間の指定はできませんが、回収日は変更可能です。
原則として、当社のサーバーはオンサイトサービスが付随しており、購入時にご要望に応じて、保証期間を設定させて頂きます。納品から5年までは保証の延長が可能ですが、6年目,7年目の保証については注意が必要です。購入時点でそれを購入するのではなく、運用中に延長保証サービスとして購入する場合には、交換パーツの在庫状況などを勘案して、延長できない可能性があることに注意してください。また、保証期間内に保証を延長する場合と、保証期間が切れてから保証を延長する場合では、価格が異なる場合があることにも注意が必要です。
修理パーツの持ち込み/持ち帰りサービス
新型コロナウイルスの流行以来、テレワークが本格的に導入されている職場も多い状況です。パーツの受け取りは、修理日と同日であることが多いので、あまり問題にならないのですが、パーツの返却は修理日と別なので、返却のためにわざわざ出勤しなければならないということもあるでしょう。そのような状況を回避するために、「修理パーツの持ち込み/持ち帰りサービス」をオプションで追加することが可能な場合があります。詳しくは、弊社営業までお問い合わせください。
オンサイト診断サービス
DELL社が手配をするエンジニアによって、オンサイトで障害原因の切り分けやファームウェアのアップデート等の作業を行います。サーバーフリーズ時のリセット対応や、ログの採取など障害解決のためのトラブルシューティングと、その診断を行うサービスです。サーバー等の設置先が遠距離で、物理的な操作が必要なときなどに利用すると便利なサービスです。
ハード ドライブ返却不要サービス/コンポーネント返却不要サービス
本サービスをご利用のお客様は、対象修復作業に基づいて交換用ハードドライブを受け取る際に、故障したハード ドライブ(PCIe や NVMe を含む、標準、ソリッド ステート ドライブ(SSD)およびシリアル ATA(SATA)ハード ディスク ドライブ(HDD))の占有権を維持できます。
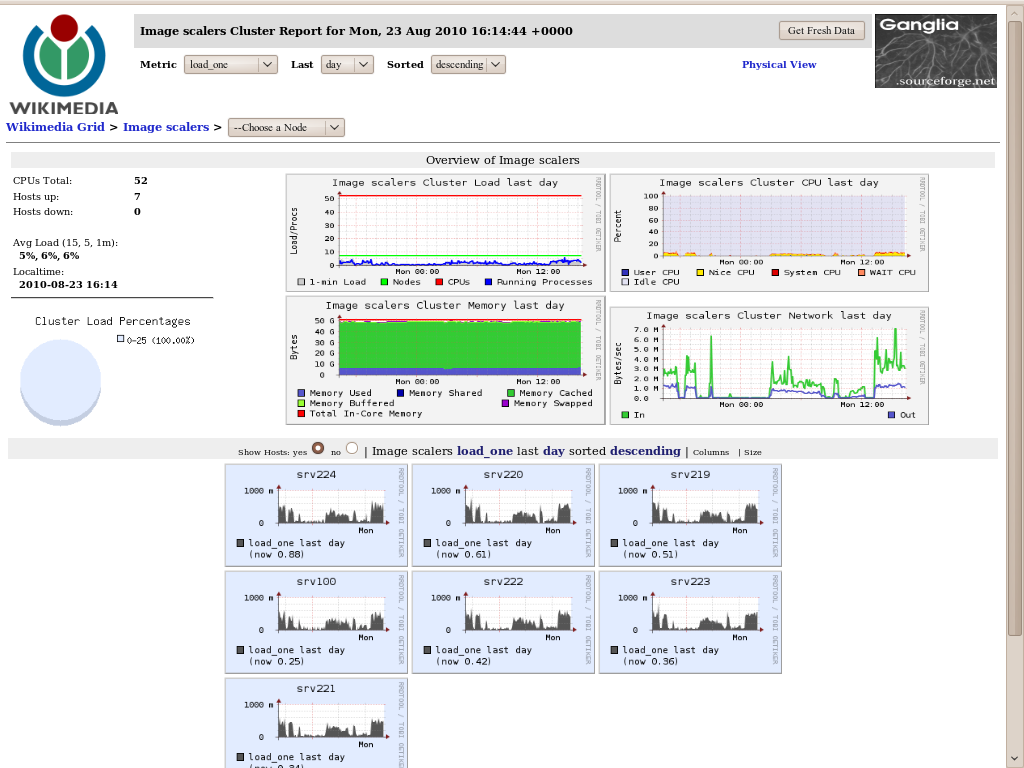
GangliaやNagiosによる Linux サーバーのリソース及び死活監視
サーバーやネットワーク、ストレージなどの負荷状況やリソースの利用状況、死活監視などを、Web GUIを通して、グラフィカルに表示することが可能です。これらのツールを利用することで、システムの負荷状況や潜在的なボトルネックを把握することが可能となり、障害原因の特定や、障害の予防に大きく役立ちます。
データの冗長性とバックアップ
HPCテクノロジーズのストレージシステムは、原則としてRAID6の冗長性をもって構成されています。RAIDとは、以下のような特徴をもちます。
RAID 0: ストライピングと呼ばれる技術を使用し、複数のディスクにデータを分散して書き込みます。これにより、パフォーマンスが向上しますが、冗長性はありません。
RAID 1: ミラーリングと呼ばれる技術を使用し、2つのディスクに同じデータを書き込みます。これにより、1つのディスクが故障してもデータは失われません。しかし、必要なディスク容量は2倍になります。
RAID 5: パリティ(冗長性情報)を使用して冗長性を提供します。データとパリティはストライピングされ、複数のディスクに分散されます。これにより、1つのディスクが故障してもデータは失われません。
RAID 6: RAID 5と同様ですが、2つのパリティ情報が使用されます。これにより、2つのディスクが同時に故障してもデータは失われません。
弊社のストレージは、原則としてRAID6で構成されていて、HDDの障害に対して高い耐障害性をもちますが、データはバックアップを取得頂くのが基本です。バックアップのリソースがあることが前提になりますが、バックアップについては、rsyncをcronで設定し、データの差分バックアップと同期を定期的に自動実行させることも可能です。
停電対応
複数のサーバー、ストレージ、無停電電源装置が組み合わされたシステム全体の起動及び停止は、日常的に行われるものではないため、その手順やトラブルシューティングに困難が伴うのはよくあることです。また、サーバーやストレージは、連続運転の場合よりも、電源をON/OFFした場合の方が障害が発生しやすい傾向にあり、停電明けの復電の際に、ディスクが壊れたり、電源が起動しないということも、ままあります。
そのような停電の場合に現地に伺い、システムの停止や起動を弊社のエンジニアが対応させて頂くサービスもございます。そのようなタイミングでOSやファームウェアのアップデートを行うことも、とても有用なことです。もちろん、システムの不具合が発生した場合には、不具合の分析やログの採取などもエンジニアが直接対応できますので、お客様のお手を煩わせることはございません。
まとめ
本稿では、弊社のHPC-ProServer、HPC-ProStorage等のエンタープライズ製品を導入頂いた場合に、どのようなサービスがご提供可能なのかという点について網羅的に記述しました。これらは、標準サービスの範囲を超える内容のものが多く含まれていますが、弊社がどのようなサービスをご提供可能なのかということについて御理解を頂き、お客様のご要望を伺いながら、導入するシステムに対するサービスをきめ細かく検討していくための、たたき台となれば幸いです。